Estimation of CX with MutliTreatment DLM
This notebook presents the estimation of cx case with MultitreatmentIRM model
The problem
When analyzing customer experience, we encounter the problem that there may be multiple impacts that overlap. We can no longer encode treatments binary, so we create groups of unique clients that do not overlap. Let's look at an example from a large fintech company.
We think the effect depends on how users were exposed to the product.
We segmented users and now want to estimate the effect for each group.
-
Target
y— binary target variable representing product utilization.
-
Treatments (problems)
neg_contact_flg— negative contact to supporterror_flg— repeat application / error flag of application.neg_contact_flg_error_flg— joint treatment where both problem flags are present.control— baseline group with no problem flag.
-
Strong confounders (past applications/utilization history)
prev_apps— past applications.prev_util— past utilization events.
-
Features (covariates)
age— age.risk_latent— latent risk factor.income— income.sessions_30d— sessions in the last 30 days.clicks_7d— clicks in the last 7 days.n_products— number of products.has_debt— debt flag.csat_prev— previous CSAT score.prev_contact— past contact history.prev_repeat— past repeat-application history.channel— application channel, represented in the generated dataset as one-hot columns:channel_callcenter,channel_partner,channel_webwithappas the reference level.region— region, represented in the generated dataset as one-hot columns:region_B,region_C,region_DwithAas the reference level.
-
Noise features
product_emb_1,product_emb_2— no-signal features.
Data
| y | control | neg_contact_flg | error_flg | neg_contact_flg_error_flg | age | risk_latent | income | sessions_30d | clicks_7d | ... | m_neg_contact_flg_error_flg | m_obs_neg_contact_flg_error_flg | tau_link_neg_contact_flg_error_flg | g_control | g_neg_contact_flg | g_error_flg | g_neg_contact_flg_error_flg | cate_neg_contact_flg | cate_error_flg | cate_neg_contact_flg_error_flg | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 40.0 | 0.612945 | 127181.894679 | 3.0 | 18.0 | ... | 0.470037 | 0.470037 | -0.65 | 0.800935 | 0.800935 | 0.677465 | 0.677465 | 0.0 | -0.123470 | -0.123470 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 26.0 | -1.690640 | 43362.759375 | 8.0 | 5.0 | ... | 0.072174 | 0.072174 | -0.65 | 0.230696 | 0.230696 | 0.135359 | 0.135359 | 0.0 | -0.095337 | -0.095337 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 45.0 | -0.288110 | 117069.035626 | 11.0 | 18.0 | ... | 0.089019 | 0.089019 | -0.65 | 0.362256 | 0.362256 | 0.228714 | 0.228714 | 0.0 | -0.133542 | -0.133542 |
| 3 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 47.0 | 0.441636 | 123821.130662 | 14.0 | 16.0 | ... | 0.341129 | 0.341129 | -0.65 | 0.716481 | 0.716481 | 0.568828 | 0.568828 | 0.0 | -0.147653 | -0.147653 |
| 4 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 18.0 | -0.722611 | 36012.152571 | 8.0 | 18.0 | ... | 0.067662 | 0.067662 | -0.65 | 0.212228 | 0.212228 | 0.123300 | 0.123300 | 0.0 | -0.088928 | -0.088928 |
5 rows × 44 columns
Ground truth ATE for neg_contact_flg vs control is 0.0 Ground truth ATE for error_flg vs control is -0.12500559719513468 Ground truth ATE for neg_contact_flg_error_flg vs control is -0.12500559719513468
MultiCausalData(df=(100000, 25), treatment_names=['control', 'neg_contact_flg', 'error_flg', 'neg_contact_flg_error_flg'], control_treatment='control')outcome='y', confounders=['age', 'risk_latent', 'income', 'sessions_30d', 'clicks_7d', 'n_products', 'has_debt', 'csat_prev', 'prev_contact', 'prev_repeat', 'prev_apps', 'prev_util', 'product_emb_1', 'product_emb_2', 'channel_callcenter', 'channel_partner', 'channel_web', 'region_B', 'region_C', 'region_D'], user_id=None,
EDA
| treatment | count | mean | std | min | p10 | p25 | median | p75 | p90 | max | |
|---|---|---|---|---|---|---|---|---|---|---|---|
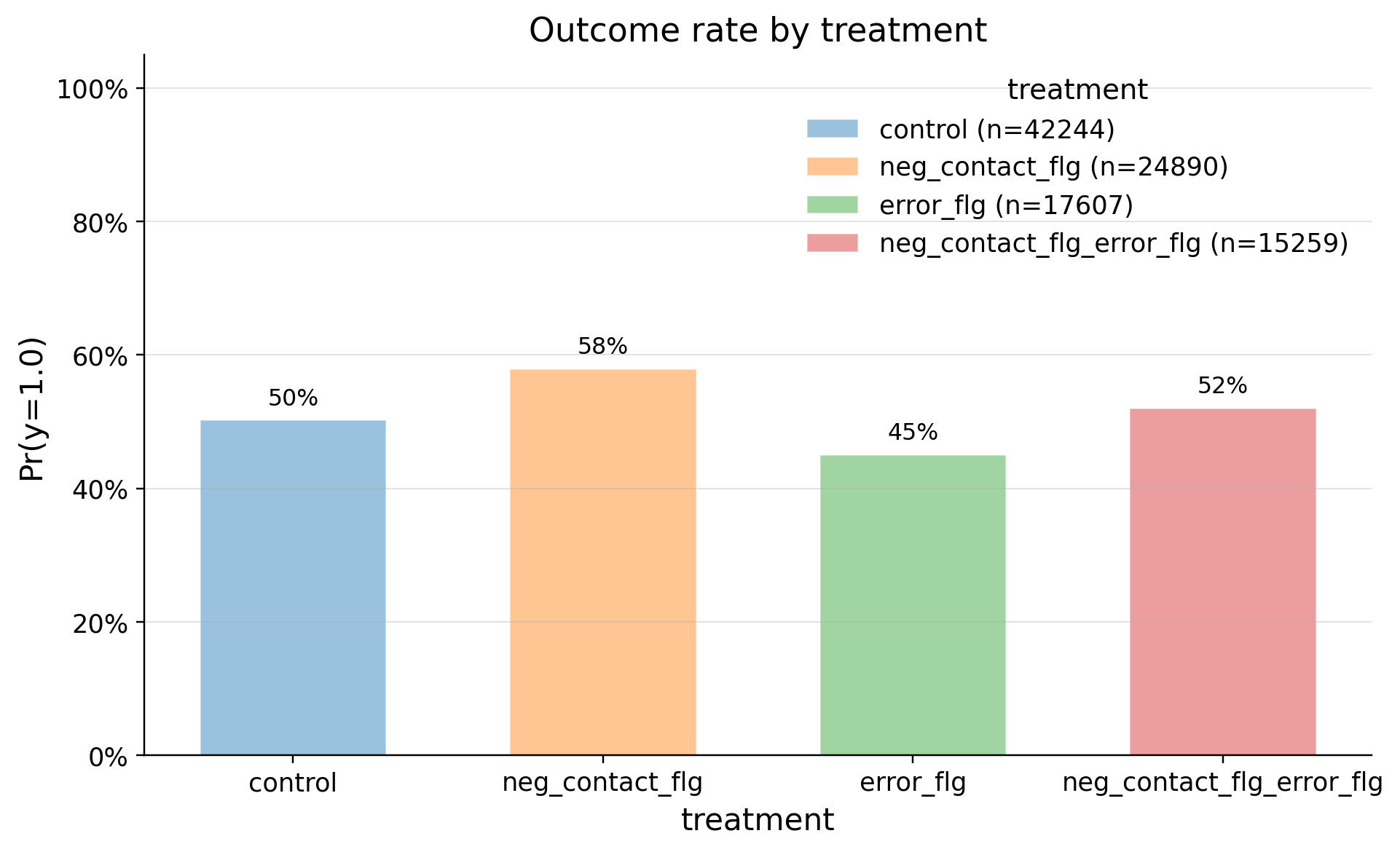
| 0 | error_flg | 17607 | 0.450162 | 0.497524 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 |
| 1 | neg_contact_flg_error_flg | 15259 | 0.519955 | 0.499618 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 2 | control | 42244 | 0.501894 | 0.500002 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 3 | neg_contact_flg | 24890 | 0.579068 | 0.493719 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| confounders | mean_d_0 | mean_d_1 | abs_diff | smd | ks_pvalue | |
|---|---|---|---|---|---|---|
| 0 | channel_web | 0.793225 | 0.017947 | 0.775278 | -2.572501 | 0.00000 |
| 1 | channel_partner | 0.000166 | 0.427500 | 0.427335 | 1.221147 | 0.00000 |
| 2 | channel_callcenter | 0.000000 | 0.088147 | 0.088147 | 0.439687 | 0.00000 |
| 3 | prev_repeat | 0.125935 | 0.301585 | 0.175650 | 0.438630 | 0.00000 |
| 4 | age | 35.862111 | 39.984608 | 4.122498 | 0.392401 | 0.00000 |
| 5 | prev_apps | 0.251373 | 0.348441 | 0.097068 | 0.213032 | 0.00000 |
| 6 | risk_latent | -0.187654 | -0.008340 | 0.179315 | 0.182731 | 0.00000 |
| 7 | prev_util | 0.323312 | 0.389220 | 0.065908 | 0.137949 | 0.00000 |
| 8 | has_debt | 0.272559 | 0.308684 | 0.036125 | 0.079622 | 0.00000 |
| 9 | clicks_7d | 13.555440 | 13.775885 | 0.220445 | 0.058115 | 0.00000 |
| 10 | prev_contact | 0.109743 | 0.092293 | 0.017451 | -0.057931 | 0.00102 |
| 11 | income | 83694.312863 | 85077.144935 | 1382.832072 | 0.045845 | 0.00000 |
| 12 | sessions_30d | 9.108370 | 9.225138 | 0.116767 | 0.037725 | 0.00241 |
| 13 | n_products | 1.868218 | 1.919123 | 0.050905 | 0.036490 | 0.00296 |
| 14 | csat_prev | 3.992626 | 3.975596 | 0.017030 | -0.029550 | 0.00931 |
| 15 | product_emb_2 | 49.475357 | 49.001533 | 0.473824 | -0.016449 | 0.02320 |
| 16 | product_emb_1 | 0.002541 | -0.013103 | 0.015644 | -0.015678 | 0.05017 |
| 17 | region_C | 0.200194 | 0.202419 | 0.002225 | 0.005550 | 1.00000 |
| 18 | region_B | 0.300469 | 0.298177 | 0.002292 | -0.005004 | 1.00000 |
| 19 | region_D | 0.148944 | 0.149770 | 0.000826 | 0.002317 | 1.00000 |
| confounders | mean_d_0 | mean_d_1 | abs_diff | smd | ks_pvalue | |
|---|---|---|---|---|---|---|
| 0 | channel_web | 0.793225 | 0.254560 | 0.538665 | -1.280740 | 0.00000 |
| 1 | prev_contact | 0.109743 | 0.487465 | 0.377721 | 0.906097 | 0.00000 |
| 2 | channel_partner | 0.000166 | 0.082523 | 0.082357 | 0.422814 | 0.00000 |
| 3 | risk_latent | -0.187654 | 0.124121 | 0.311775 | 0.317290 | 0.00000 |
| 4 | prev_apps | 0.251373 | 0.333548 | 0.082175 | 0.181385 | 0.00000 |
| 5 | sessions_30d | 9.108370 | 9.663761 | 0.555390 | 0.177521 | 0.00000 |
| 6 | prev_util | 0.323312 | 0.394777 | 0.071465 | 0.149384 | 0.00000 |
| 7 | csat_prev | 3.992626 | 3.913419 | 0.079206 | -0.135992 | 0.00000 |
| 8 | has_debt | 0.272559 | 0.313419 | 0.040860 | 0.089864 | 0.00000 |
| 9 | income | 83694.312863 | 86202.400216 | 2508.087352 | 0.083142 | 0.00000 |
| 10 | clicks_7d | 13.555440 | 13.855404 | 0.299964 | 0.079103 | 0.00000 |
| 11 | channel_callcenter | 0.000000 | 0.001326 | 0.001326 | 0.051527 | 1.00000 |
| 12 | n_products | 1.868218 | 1.913620 | 0.045402 | 0.032749 | 0.02248 |
| 13 | prev_repeat | 0.125935 | 0.116191 | 0.009744 | -0.029873 | 0.10152 |
| 14 | age | 35.862111 | 35.559301 | 0.302810 | -0.029333 | 0.01887 |
| 15 | region_B | 0.300469 | 0.296424 | 0.004044 | -0.008839 | 0.95896 |
| 16 | region_C | 0.200194 | 0.203094 | 0.002900 | 0.007227 | 0.99937 |
| 17 | product_emb_1 | 0.002541 | 0.009430 | 0.006889 | 0.006910 | 0.48216 |
| 18 | region_D | 0.148944 | 0.147690 | 0.001254 | -0.003529 | 1.00000 |
| 19 | product_emb_2 | 49.475357 | 49.430173 | 0.045185 | -0.001568 | 0.99499 |
| confounders | mean_d_0 | mean_d_1 | abs_diff | smd | ks_pvalue | |
|---|---|---|---|---|---|---|
| 0 | channel_web | 0.793225 | 0.000983 | 0.792242 | -2.758190 | 0.00000 |
| 1 | channel_callcenter | 0.000000 | 0.553837 | 0.553837 | 1.575597 | 0.00000 |
| 2 | channel_partner | 0.000166 | 0.347139 | 0.346974 | 1.030330 | 0.00000 |
| 3 | prev_contact | 0.109743 | 0.422701 | 0.312958 | 0.757096 | 0.00000 |
| 4 | risk_latent | -0.187654 | 0.321338 | 0.508992 | 0.519183 | 0.00000 |
| 5 | prev_repeat | 0.125935 | 0.293138 | 0.167203 | 0.419783 | 0.00000 |
| 6 | prev_apps | 0.251373 | 0.444525 | 0.193152 | 0.414100 | 0.00000 |
| 7 | age | 35.862111 | 39.988793 | 4.126683 | 0.394090 | 0.00000 |
| 8 | prev_util | 0.323312 | 0.472049 | 0.148737 | 0.307469 | 0.00000 |
| 9 | sessions_30d | 9.108370 | 9.892260 | 0.783890 | 0.247583 | 0.00000 |
| 10 | csat_prev | 3.992626 | 3.888356 | 0.104270 | -0.179496 | 0.00000 |
| 11 | has_debt | 0.272559 | 0.355004 | 0.082444 | 0.178372 | 0.00000 |
| 12 | income | 83694.312863 | 88186.376248 | 4492.063384 | 0.147876 | 0.00000 |
| 13 | clicks_7d | 13.555440 | 14.052297 | 0.496857 | 0.130705 | 0.00000 |
| 14 | n_products | 1.868218 | 1.942788 | 0.074570 | 0.053441 | 0.00024 |
| 15 | region_C | 0.200194 | 0.204863 | 0.004669 | 0.011617 | 0.96653 |
| 16 | region_B | 0.300469 | 0.303624 | 0.003155 | 0.006872 | 0.99987 |
| 17 | product_emb_2 | 49.475357 | 49.635494 | 0.160136 | 0.005543 | 0.75707 |
| 18 | product_emb_1 | 0.002541 | 0.005789 | 0.003248 | 0.003255 | 0.80490 |
| 19 | region_D | 0.148944 | 0.149682 | 0.000738 | 0.002070 | 1.00000 |
Training the Model and Reviewing the Results
| neg_contact_flg vs control | error_flg vs control | neg_contact_flg_error_flg vs control | |
|---|---|---|---|
| field | |||
| estimand | ATE | ATE | ATE |
| model | MultiTreatmentIRM | MultiTreatmentIRM | MultiTreatmentIRM |
| value | -0.0036 (ci_abs: -0.0067, -0.0005) | -0.1220 (ci_abs: -0.1258, -0.1182) | -0.1141 (ci_abs: -0.1174, -0.1108) |
| value_relative | -0.6415 (ci_rel: -1.1946, -0.0883) | -21.8757 (ci_rel: -22.5073, -21.2442) | -20.4580 (ci_rel: -20.9967, -19.9193) |
| alpha | 0.0500 | 0.0500 | 0.0500 |
| p_value | 0.0233 | 0.0000 | 0.0000 |
| is_significant | False | True | True |
| n_treated | 24890 | 17607 | 15259 |
| n_control | 42244 | 42244 | 42244 |
| treatment_mean | 0.5791 | 0.4502 | 0.5200 |
| control_mean | 0.5019 | 0.5019 | 0.5019 |
| time | 2026-04-15 | 2026-04-15 | 2026-04-15 |
"Error" or "Negative Contact + Error" decreases probability to utilization in product by 11 p.p
Refutation
| comparison | n_pair | n_treated | n_baseline | edge_0.01_below | edge_0.01_above | ks | auc | ess_ratio_treated | ess_ratio_baseline | ... | clip_m_baseline | clip_m_total | flag_edge_001 | flag_ks | flag_auc | flag_ess_treated | flag_ess_baseline | flag_clip_m | overall_flag | pass | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
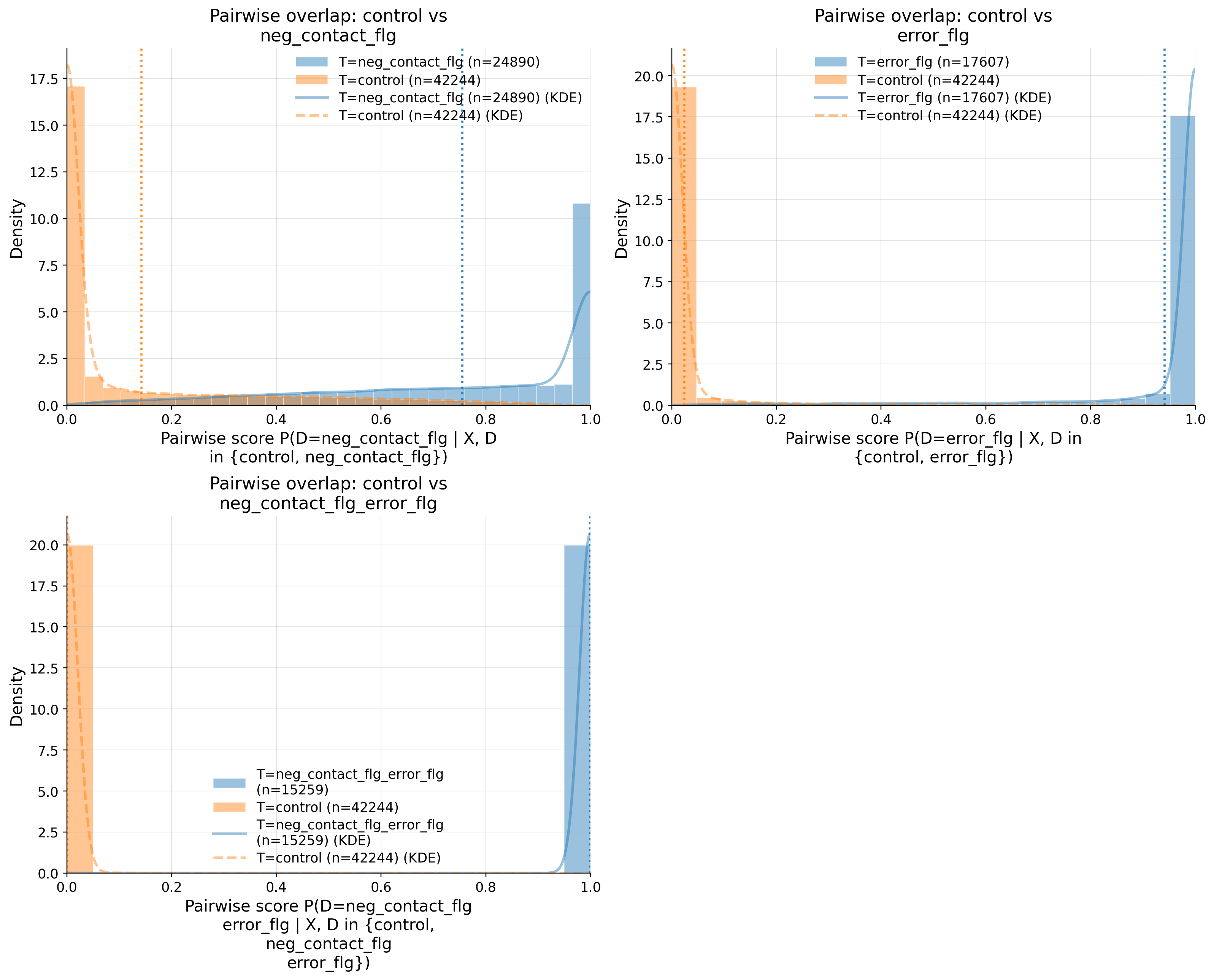
| 0 | control vs neg_contact_flg | 67134 | 24890 | 42244 | 0.296273 | 0.125659 | 0.718263 | 0.945453 | 0.348940 | 0.165737 | ... | 0.131737 | 0.429499 | RED | RED | RED | GREEN | YELLOW | RED | RED | False |
| 1 | control vs error_flg | 59851 | 17607 | 42244 | 0.606773 | 0.221584 | 0.950640 | 0.998057 | 0.305756 | 0.165737 | ... | 0.227715 | 0.849643 | RED | RED | RED | GREEN | YELLOW | RED | RED | False |
| 2 | control vs neg_contact_flg_error_flg | 57503 | 15259 | 42244 | 0.726136 | 0.263899 | 0.999834 | 1.000000 | 0.283149 | 0.165737 | ... | 0.265151 | 0.999409 | RED | RED | RED | YELLOW | YELLOW | RED | RED | False |
3 rows × 25 columns
| comparison | metric | value | flag | |
|---|---|---|---|---|
| 0 | control vs neg_contact_flg | edge_0.01_below | 0.296273 | RED |
| 1 | control vs neg_contact_flg | edge_0.01_above | 0.125659 | RED |
| 2 | control vs neg_contact_flg | KS | 0.718263 | RED |
| 3 | control vs neg_contact_flg | AUC | 0.945453 | RED |
| 4 | control vs neg_contact_flg | ESS_treated_ratio | 0.34894 | GREEN |
| 5 | control vs neg_contact_flg | ESS_baseline_ratio | 0.165737 | YELLOW |
| 6 | control vs neg_contact_flg | clip_m_total | 0.429499 | RED |
| 7 | control vs neg_contact_flg | overlap_pass | False | RED |
| 8 | control vs error_flg | edge_0.01_below | 0.606773 | RED |
| 9 | control vs error_flg | edge_0.01_above | 0.221584 | RED |
| 10 | control vs error_flg | KS | 0.95064 | RED |
| 11 | control vs error_flg | AUC | 0.998057 | RED |
| 12 | control vs error_flg | ESS_treated_ratio | 0.305756 | GREEN |
| 13 | control vs error_flg | ESS_baseline_ratio | 0.165737 | YELLOW |
| 14 | control vs error_flg | clip_m_total | 0.849643 | RED |
| 15 | control vs error_flg | overlap_pass | False | RED |
| 16 | control vs neg_contact_flg_error_flg | edge_0.01_below | 0.726136 | RED |
| 17 | control vs neg_contact_flg_error_flg | edge_0.01_above | 0.263899 | RED |
| 18 | control vs neg_contact_flg_error_flg | KS | 0.999834 | RED |
| 19 | control vs neg_contact_flg_error_flg | AUC | 1.0 | RED |
| 20 | control vs neg_contact_flg_error_flg | ESS_treated_ratio | 0.283149 | YELLOW |
| 21 | control vs neg_contact_flg_error_flg | ESS_baseline_ratio | 0.165737 | YELLOW |
| 22 | control vs neg_contact_flg_error_flg | clip_m_total | 0.999409 | RED |
| 23 | control vs neg_contact_flg_error_flg | overlap_pass | False | RED |
Because “bad overlap” and “accurate point estimate” are different things here.
- Your overlap is genuinely bad, not a plotting bug. The notebook diagnostics are extreme:
KS = 0.716 / 0.951 / 0.9997,AUC = 0.945 / 0.998 / 1.0, andclip_m_total = 0.43 / 0.85 / 0.999for the three pairwise comparisons. That means the arms are almost perfectly separable in propensity space. - This is expected from the CX DGP. Treatment assignment is intentionally very predictable from observed history:
prev_contactenters the contact logit with coefficient2.20,prev_repeatenters the repeat logit with coefficient1.30, and the joint arm literally usescontact_logit + repeat_logitas its score. So near-deterministic assignment is baked into the benchmark. - The outcome side is much easier than the treatment side. In this DGP the treatment effects are constant on the link scale:
theta=[0.0, 0.0, -0.65, -0.65]andtau=[None, None, None, None]. Soneg_contact_flgtruly has zero effect, anderror_flgandneg_contact_flg_error_flghave the same effect by construction. - There is also no hidden confounding in the generator defaults:
u_strength_y=0.0andu_strength_d=0.0. So all the variables driving treatment are observed inX, which makes the synthetic problem much friendlier than real data. MultiTreatmentIRMis not pure IPW. Its score is orthogonal / AIPW-style, combining outcome regressiong_hatwith residual weighting by1 / m_hat. Ifg_hatis learned well, the ATE can still be accurate even when overlap is weak.- You also have a huge sample. Even with poor overlap, the ESS ratios still leave thousands of effective observations: roughly
9.6k,5.3k, and3.8ktreated ESS, with about11.3kbaseline ESS in each comparison. That is plenty for a simple constant-effect synthetic DGP.
One subtlety: the overlap plot and overlap diagnostics prefer m_hat_raw when available, while estimation uses trimmed m_hat with threshold 0.01. So the diagnostic picture is intentionally harsher than the exact weights used in the score.
The takeaway is: this overlap is bad, but the estimate is still close to oracle because the benchmark is very favorable to outcome-model-based recovery. In real data, overlap this bad would make me treat the result as fragile and model-dependent, not reassuring. Your later sensitivity section is consistent with that: the bias-aware intervals get much wider even though the sampling CI is tight.
If you want, I can next help you answer one of these precisely:
- whether the estimate is mostly coming from
g_hatrather than IPW, - how much trimming is rescuing the estimate,
- how to soften this DGP so overlap becomes realistic.
Unconfoundedness
| comparison | metric | value | flag | |
|---|---|---|---|---|
| 0 | control vs neg_contact_flg | balance_max_smd | 0.757665 | RED |
| 1 | control vs neg_contact_flg | balance_frac_violations | 0.25 | RED |
| 2 | control vs neg_contact_flg | balance_pass | False | RED |
| 3 | control vs error_flg | balance_max_smd | 1.653832 | RED |
| 4 | control vs error_flg | balance_frac_violations | 0.45 | RED |
| 5 | control vs error_flg | balance_pass | False | RED |
| 6 | control vs neg_contact_flg_error_flg | balance_max_smd | 1.957133 | RED |
| 7 | control vs neg_contact_flg_error_flg | balance_frac_violations | 0.65 | RED |
| 8 | control vs neg_contact_flg_error_flg | balance_pass | False | RED |
| 9 | overall | balance_max_smd | 1.957133 | RED |
| 10 | overall | balance_frac_violations | 0.45 | RED |
| 11 | overall | balance_pass | False | RED |
| control vs neg_contact_flg | control vs error_flg | control vs neg_contact_flg_error_flg | |
|---|---|---|---|
| channel_web | 1.280761 | 2.572535 | 2.758223 |
| channel_callcenter | 0.051529 | 0.439699 | 1.575648 |
| channel_partner | 0.422822 | 1.221182 | 1.030364 |
| prev_contact | 0.906113 | 0.057932 | 0.757117 |
| risk_latent | 0.317295 | 0.182735 | 0.519195 |
| prev_repeat | 0.029874 | 0.438640 | 0.419794 |
| prev_apps | 0.181388 | 0.213037 | 0.414109 |
| age | 0.029333 | 0.392409 | 0.394099 |
| prev_util | 0.149387 | 0.137952 | 0.307476 |
| sessions_30d | 0.177523 | 0.037726 | 0.247589 |
rep_uc Meaning
run_unconfoundedness_diagnostics() is checking weighted covariate balance after reweighting by the estimated multiclass propensities d_k / m_hat_k, then computing standardized mean differences (SMDs) between each treatment arm and control in It uses the trimmed m_hat from the estimate, not m_hat_raw, so this is already judging the “safer” propensities actually used by the score in
Your numbers are a hard fail:
control vs neg_contact_flg:balance_max_smd = 0.75095,balance_frac_violations = 0.30control vs error_flg:balance_max_smd = 1.655942,balance_frac_violations = 0.45control vs neg_contact_flg_error_flg:balance_max_smd = 1.924802,balance_frac_violations = 0.65- Overall:
46.7%of feature-comparison cells are still above the default SMD threshold0.10, and anything above0.20is alreadyREDby the implementation in
Why This Happens
This does not mean the DGP violates unconfoundedness. In this synthetic CX setup, unconfoundedness is true by construction because treatment and outcome depend only on observed X, with no hidden U effect by default in the shared generator at What fails is the practical balancing step induced by estimated propensities.
The reason is the treatment assignment is intentionally very sharp:
neg_contact_flgis driven strongly byprev_contactwith coefficient2.20inerror_flgis driven byprev_repeatand related history in- the joint arm uses the sum of both logits in
So the arms live in different parts of covariate space. Poor overlap means IPW cannot create balanced pseudo-populations because there just are not enough comparable controls and treated units to reweight into each other. That’s exactly why overlap and balance both fail.
Why ATE Is Still Close
The estimate can still be near oracle because MultiTreatmentIRM is doubly robust / outcome-augmented, not pure IPW. Its score combines outcome regression g_hat with weighted residual terms in . In this benchmark the treatment effect structure is very simple on the link scale, with theta=[0.0, 0.0, -0.65, -0.65] and no extra tau(X) in So g_hat can recover a lot even when weighting is weak.
That’s also why the pattern of errors makes sense:
neg_contact_flghas the least-bad overlap/balance and smallest absolute miss from oracleneg_contact_flg_error_flghas the worst overlap/balance and the biggest miss
So the clean interpretation is:
- overlap diagnostics: bad
- balance diagnostics: bad even after trimming
- oracle vs estimate: still close because this synthetic problem is easy for the outcome model, not because the design is well supported
Sensetivity analysis
| cf_y | r2_y | r2_d | rho | theta_long | theta_short | delta | |
|---|---|---|---|---|---|---|---|
| neg_contact_flg vs control | 0.00002 | 0.00002 | 0.000212 | 0.972781 | -0.003577 | 0.019615 | -0.023192 |
| error_flg vs control | 0.00002 | 0.00002 | 0.000109 | 0.888425 | -0.121998 | -0.088648 | -0.033350 |
| neg_contact_flg_error_flg vs control | 0.00002 | 0.00002 | 0.000636 | 0.889238 | -0.114092 | -0.048212 | -0.065880 |
================== Bias-aware Interval ==================
------------------ Scenario ------------------ Significance Level: alpha=0.05 Null Hypothesis: H0=0.0 Sensitivity parameters: cf_y=0.05; r2_d=[0.05 0.05 0.05], rho=[1. 1. 1.], use_signed_rr=False
statistics value 0 neg_contact_flg vs control | bias_aware_ci [-0.1581, 0.1509] 1 neg_contact_flg vs control | theta [-0.1547, -0.0036, 0.1476] 2 neg_contact_flg vs control | sampling_ci [-0.0067, -0.0005] 3 neg_contact_flg vs control | rv 0.000000 4 neg_contact_flg vs control | rva 0.000000 5 neg_contact_flg vs control | se 0.001600 6 neg_contact_flg vs control | max_bias 0.151100 7 neg_contact_flg vs control | max_bias_base 2.946100 8 neg_contact_flg vs control | bound_width 0.151100 9 neg_contact_flg vs control | sigma2 0.050800 10 neg_contact_flg vs control | nu2 170.885100 11 error_flg vs control | bias_aware_ci [-0.2885, 0.0441] 12 error_flg vs control | theta [-0.2842, -0.122, 0.0403] 13 error_flg vs control | sampling_ci [-0.1258, -0.1182] 14 error_flg vs control | rv 0.028900 15 error_flg vs control | rva 0.027200 16 error_flg vs control | se 0.001900 17 error_flg vs control | max_bias 0.162200 18 error_flg vs control | max_bias_base 3.162800 19 error_flg vs control | bound_width 0.162200 20 error_flg vs control | sigma2 0.050800 21 error_flg vs control | nu2 196.951700 22 neg_contact_flg_error_flg vs control | bias_aware_ci [-0.2935, 0.0649] 23 neg_contact_flg_error_flg vs control | theta [-0.2897, -0.1141, 0.0615] 24 neg_contact_flg_error_flg vs control | sampling_ci [-0.1174, -0.1108] 25 neg_contact_flg_error_flg vs control | rv 0.021700 26 neg_contact_flg_error_flg vs control | rva 0.020500 27 neg_contact_flg_error_flg vs control | se 0.001700 28 neg_contact_flg_error_flg vs control | max_bias 0.175600 29 neg_contact_flg_error_flg vs control | max_bias_base 3.423000 30 neg_contact_flg_error_flg vs control | bound_width 0.175600 31 neg_contact_flg_error_flg vs control | sigma2 0.050800 32 neg_contact_flg_error_flg vs control | nu2 230.695800
Summary
A regular contact/support request is not a problem, while submitting the application multiple times leads to a decrease in product utilization.